アップロードされたすべてのファイルを全て抽出する
他サイトを丸ごとコピーする方法 どんなソフトを使うよりも、これが一番すごい! それは「wget」コマンド基本的な使い方
ひとつのファイルをダウンロードするだけなら、コマンドラインで URL を指定するだけです。wget http://webos-goodies.jp/index.htmlこれで指定したファイルがダウンロードされ、カレントディレクトリに保存されます。
サイトの内容を丸ごとダウンロードしたいときは、 "-r" (リンクを辿って再帰的にダウンロード)、 "-k" (リンクを相対パスに変換)、 "-E" (text/html のファイルに拡張子 ".html" を付加)といったオプションを付けて、サイトのトップページの URL を指定します。
wget -r -k -E http://webos-goodies.jp/index.html今度はカレントディレクトリにドメイン名と同じ名前のディレクトリが作成され、その下にサイトと同じ構成で各ファイルが保存されます。画像や CSS, JavaScript などもダウンロードされますので、元のレイアウトがほぼそのまま再現されるはずです。ただし、デフォルトではリンクを辿るのは 5 階層までで、他のドメインへのリンクは無視されます。このあたりはシチュエーションに合わせて後述のオプションで調整してください。
wget のコマンドラインオプション
wget にはとてもたくさんのオプションがあり、とてもすべては掲載しきれません。ここではサイトのダウンロードに使いそうなものに絞ってご紹介しますので、ご了承ください。
HTTP アクセスの制御
今回の目的に直接関係する部分ですね。主に HTTP リクエストヘッダの内容を指定するものです。
| --http-user=str | BASIC 認証のユーザー名を指定 | |
| --http-password=str | BASIC 認証のパスワードを指定 | |
| --load-cookies file | 送信する Cookie を file から読み込む | |
| --ignore-length | Content-Length が間違っていてもリトライしない | |
| --referer=url | リファラーを指定 | |
| -U | --user-agent=str | User Agent を指定 |
| --header=str | HTTP ヘッダを追加 |
再帰ダウンロードの制御
再帰ダウンロード時にリンクを辿る条件などを指定するオプションです。
| -r | --recursive | 再帰的にリンクを辿る |
| -l | --level=n | リンクを辿る階層を n までに制限(デフォルト 5) |
| -np | --no-parent | 上位階層へのリンクは辿らない |
| -L | --relative | 相対リンク以外は辿らない |
| --follow-ftp | FTP リンクを辿る | |
| -p | --page-requisites | HTML の表示に必要なファイルをダウンロードする |
| -H | --span-hosts | 別ドメインへのリンクも辿る |
| -D | --domain=list | リンクを辿るドメインを指定 |
| --exclude-domains list | リンクを辿らないドメインを指定 | |
| -A | --accept list | 指定したパターンのファイル名のみダウンロード |
| -R | --reject list | 指定したパターンのファイル名を拒否 |
| -I | --include-directories=list | ダウンロードを許可するディレクトリリストを指定 |
| -X | --exclude-directories=list | ダウンロードを拒否するディレクトリリストを指定 |
| -m | --mirror | -r -N -l inf --no-remove-listing と等価 |
ダウンロード・保存の制御
更新チェックや保存時の変換などを制御するオプションです。
| -nc | --no-clobber | 既に存在するファイルは無視する |
| -N | --timestamping | 日付やサイズを比較して変更なければ無視する |
| -nH | --no-host-directories | ホスト名のディレクトリを作らない |
| --cut-dirs=n | 保存時に上位 n 階層のディレクトリを作らない | |
| -E | --html-extension | HTML ファイルに拡張子 ".html" を付加する |
| -k | --convert-line | HTML 中のリンクを相対指定に書き換える |
| -K | --backup-converted | ファイルを書き換えた際にバックアップを作成 |
これ以外にもたくさんあります。詳細は man ページなどをご参照ください。
認証をパスする方法
さて、いよいよ本題、 wget で認証付きサイトにアクセスする方法をご紹介します。いくつか方法があるので、場合によって使い分けてください。
BASIC 認証の場合
サイトの認証方法が BASIC 認証(ブラウザ標準のダイアログが表示される認証方法)を使っているなら、話は簡単です。前述の "--http-user", "--http-password" のオプションにユーザー名とパスワードを指定するだけでパスできます。例えば、以下のような感じです。
wget --http-user="ユーザー名" --http-password="パスワード" \
http://webos-goodies.jp/index.html
必要に応じて前述のオプションを追加して、必要なファイルをダウンロードしてください。
永続的な Cookie による認証の場合
永続的な Cookie にセッションキーを保存するタイプの Web サイトに使える方法です。ブラウザを閉じてもログイン状態が持続するサイトはこちらのタイプかもしれません。ただし、すべてではありませんので、もし認証が通らなかった場合は後述の「セッション Cookie による認証」の方法を試してみてください。
このタイプの場合、ブラウザが保存する Cookie ファイルを "--load-cookies" オプションに渡すことで、認証をパスできます。 Firefox の場合は以下の手順で Cookie ファイルが取得できます。
- Firefox を起動し、対象の Web サイトにログインする。
- ログイン状態のまま Firefox を終了する。
- Firefox のプロファイルディレクトリにある "cookies.txt" が Cookie ファイルになります。
IE の場合は、以下の手順になります。
- IE を起動し、対象の Web サイトにログインする。
- メニューから [ファイル]-[インポートおよびエクスポート]を選択。
- ウィザードに従い、 Cookie をファイルにエクスポートする。
- エクスポートされたファイルが Cookie ファイルになります。
いずれの場合も、取得した Cookie ファイル(ここでは "cookies.txt" とする)を以下のように指定すれば OK です。
wget --load-cookies=cookies.txt http://webos-goodies/index.html
残念ながら Opera / Safari で Cookie ファイルをエクスポートする方法はわかりませんでした。情報求む。
セッション Cookie による認証
セッション Cookie (ブラウザを閉じると削除される Cookie)にセッション ID を保存するタイプです。セッション Cookie は前述の cookies.txt には保存されないので、その内容を取得するのにはひと工夫必要です。 Opera や Firefox なら Cookie マネージャで Cookie の内容を見ることができますが、ちょっと面倒です。ここでは Firebug を使う方法をご紹介しましょう。
まずは、 Firebug をインストールした Firefox を起動し、対象の Web サイトにログインしてください。そして Firebug の Net タブを開き、ページをリロードします。多数のファイルが読み込まれてグラフが表示されると思いますが、その一番上(ページの HTML ファイル)の "+" をクリックして情報を表示させてください。
Response Headers と Request Headers が表示されますので、 Request Headers の Cookie の値(下の画像の赤線の部分、実際にはもっと長い文字列のはず)をコピーしてください。
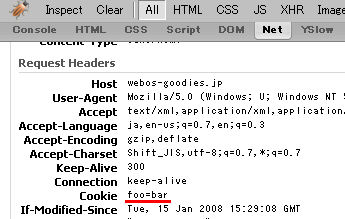
あとは、 wget のコマンドラインにその文字列(ここでは "foo=bar")を以下のように指定すれば OK です。
wget --header 'Cookie: foo=bar' http://webos-goodies.jp/index.html
これで指定した Cookie が送出され、認証をパスできます。この文字列には永続的な Cookie も含まれていますので、 Cookie で認証を行うサイトすべてにこの方法が使えます。 Firebug がインストールされているなら、こちらの方が簡単かもしれませんね。
注意点・ Tips など
最後に、私が気付いた点をいくつか挙げておきます。
- 上記の方法で認証がパスできない場合は、 User Agent をログインに使ったブラウザと同じものにしたり、リファラーにサイト内のページを指定したりするといいかもしれません。
- CSS 内のリンクは辿らないので、 background-image などで表示されている画像はダウンロードされない事があります。
- 画像などが他のドメインに保存されている場合は、 "-H", "-D" オプションなどでダウンロード対象のドメインを指定する必要があります。
- Ajax を活用したサイトなどはダウンロードしても正常に機能しないでしょう。
- 大量のダウンロードはサーバーに高い負荷をかけます。サイト所有者に迷惑をかけないようにご注意ください。
wgetコマンドで複数のファイルを同時に取得する
wget -i file
fileの中身
<<
http://hisashi.me/edit_siteopen.php
http://hisashi.me/list_main_plan.php
>>
![クーロンのログ、プロセスの検索・終了[ubunt]](https://blog.hisashi.me/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)








